2010s Cloud vs 2026 Agents
A first-person history of the decade that built modern cloud computing, told through the IaaS panels, hypervisor wars, datacenter automation moves, and open-source revolts that I lived through as a student and operator in Istanbul.
In 2010, I had a physical prepaid card sitting on my LG laptop. It was worth twenty-five US dollars, it had the word Terremark printed across the top, and it was the credential I needed to spin up a virtual server in a public cloud. The thing you would call “cloud” today did not exist in any consumer sense. The companies running what we now treat as the default plumbing of the internet were small enough that you could meet their entire engineering team at a conference, and most of them are now dead or absorbed. You used to receive their beta invites in an envelope.
I have been holding on to that photo for fifteen years. I posted it again last year because I think people forget what the cloud actually looked like when it was being built. Cloud computing in the early 2010s was not the abstract layer you treat as an axiom today. It was a thing that real companies were physically inventing while you watched, with cards in the mail, half-broken control panels, and competing visions of what infrastructure should even feel like.

Back in 2010, before AWS ate the world, we were using ‘cloud’ from providers don't even exist today. Companies were experimenting and shaping IaaS. Here I am beta testing Terremark vCloud with a prepaid invite card, because that was the future.

A retrospective I posted in 2025. The company in the address line on my screen is now part of Verizon Cloud and the vCloud Express product was wound down years ago.
I spent the 2010s inside the cloud. Not as a customer who clicked Sign up for AWS and got a bill. As a person who was reading the launch notes the morning they shipped, integrating the APIs the same week, and writing about each move on Turkish blogs and Twitter at a time when those posts were the closest thing my country had to a trade press for cloud infrastructure. I was a student. I was operating servers for clients. I was building panels that talked to hypervisors before there was a category name for what I was doing. I did this for ten years and then quietly carried the patterns into building agent infrastructure for AI systems in 2025 and 2026, where, it turns out, every problem rhymes.
This is the long version of what I saw.
Before the cloud, there was the rack
In 2008, when I started this work, IT looked like this. You phoned a Dell or HP reseller in Istanbul. You ordered a 1U server with two Xeons, sixteen gigabytes of RAM and a pair of mirrored SAS disks. It arrived in three to ten weeks depending on whether anyone remembered to push the order. You drove it to a colocation facility, racked it, ran a Cat 6 cable to your switch, hung a label on it, walked back to your desk, and started installing CentOS over a serial console. There was no console redirection from your home. There was no cloud-init. The networking was switch-level VLANs and BGP that you negotiated with the carrier in person. If a fan died, your phone rang.
Spinning up “another web server” was a project that started with a procurement meeting. Spinning up “ten more web servers” was a project that started with a board meeting. Capacity planning was a separate discipline because the cost of being wrong was buying iron you did not need.
VMware vSphere had just become indispensable. ESX 3.5 was 2007. ESX 4 / vSphere 4 was 2009. You could finally take a single physical machine and run twenty virtual machines on it, with vCenter giving you live migration, HA, distributed switches. This was, in 2008, the revolution in operations. The reason people in this industry kept saying “virtualization is changing everything” was because virtualization was changing everything. The rest of what we now call cloud was the next step beyond that, and most of us could see it coming on the horizon, we just did not know it would arrive as fast as it did or in the shape it did.
The thing that needed to break next was the supply chain. The wait from “we need a new server” to “the server is racked and serving traffic” was the bottleneck on every interesting project in 2009. That bottleneck was about to get destroyed by a Miami-based VMware partner handing out prepaid cloud invites and by a company in Seattle quietly turning a server-rental side project into the substrate that ran everything else.
The first cloud panels (2010 to 2011)
By the spring of 2010, you could pick from a handful of public clouds. Amazon Web Services was the giant in the room. They had launched EC2 in 2006 and had spent four years adding S3, EBS, SimpleDB, CloudFront, Route 53, and a usable Free Tier (announced November 2010). They were already three years ahead. But the rest of the market mattered too, because nobody in Turkey was ready to wire their entire infrastructure to a single US provider, and the latency from us to us-east-1 was real.
Rackspace had Cloud Servers and Cloud Files. The cofounder Jonathan Bryce had announced Cloud Servers in 2008. By 2010 they were a credible alternative for anyone wanting Linux instances with a UI that did not look like a NASA console. Terremark, headquartered in Miami, had Enterprise Cloud and the smaller, friendlier vCloud Express, both built on VMware. GoGrid, Joyent, BlueLock, and a long tail of regional players were trying every variant.
The control panels these companies shipped were terrible in a very specific 2010 way. Bootstrap was not released until August 2011. jQuery 1.4 was the cutting edge. The Rackspace and Terremark panels were dense HTML tables, often three frames deep, sometimes built on Adobe Flex because Flash was still the easiest way to ship a “professional” web UI. You would log in, see a list of instances with green and red dots, click a name, and get a page that took six seconds to load and looked like it had been bolted onto an older shared-hosting product. Which is exactly what most of them were.
But the idea was right. The idea was: a credit card and an API key replace a procurement meeting. Provisioning takes three minutes instead of three weeks. The cost model becomes operational instead of capital. The unit of infrastructure is a virtual machine, not a 1U box. You can hate the panel and still understand that the world had just changed.
I spent 2010 writing articles in Turkish trying to explain what the deployment models were. I had to translate “IaaS” and “PaaS” and “SaaS” because the terms did not have agreed Turkish equivalents. I also went and organized the conference where the rest of the local hosting industry would have to listen. Türkiye Hosting Zirvesi was an event I put together at Istanbul Kültür University in April 2010, partly to argue that hosting companies in our region needed to understand that the shape of their product was about to change, fast, and most of them were not building the right thing. The event continued the year after.
Son hazirliklar... :)
“Final preparations.” The night before Hosting Zirvesi 2011. The attached photo on the original tweet sat on TwitPic, which was wound down in 2014, so the image is lost; the timestamp survives.
A few months later, the international providers started making the moves I had been telling people to expect. Rackspace turned on its UK infrastructure, and the latency from Turkey suddenly became usable.
Rackspace'in İngiltere altyapısı tamamiyle devreye girdi. Türkiye'den erişim çok iyi deneyebilirsiniz.
“Rackspace's UK infrastructure is fully online. Access from Turkey is excellent, give it a try.” For anyone serving European traffic from Istanbul, this was the first non-US cloud option that did not cost a fortune in transit.
The OpenStack project was announced in July 2010. Rackspace and NASA had decided that the entire control plane of a public cloud should be open source. They open-sourced Nova (compute, from NASA’s Nebula project) and Swift (object storage, from Rackspace Cloud Files). The first stable release, Austin, came out in October. By January 2011 the project was already six months old and clearly bigger than what most observers had thought it would be.
Openstack 6. ayini doldurmuş. Devamı için daha güzel gelişmeler duyarız umarım.
“OpenStack just hit its six-month mark. Hoping for even better news from here.” Posted four months after the Austin release and one month before Bexar.
The day after, Amazon shipped the product that made the next decade of cloud computing inevitable: Elastic Beanstalk. This was the moment AWS stopped being a server-rental business and started being a platform.
Amazon PaaS dünyasına resmen adım attı.
“Amazon has officially stepped into the PaaS world.” Posted two days after AWS announced Elastic Beanstalk, the first AWS-native PaaS offering and a clear shot at Heroku and Google App Engine.
Most people remember AWS as a single straight-line success story. It was not. By 2011, AWS had been a “successful server-rental business” for five years. Beanstalk was the moment they declared that the abstraction was going up the stack. The interesting question stopped being “do you want a Linux box on the internet” and started being “what is the lowest level of detail you are willing to manage”. Some of you would manage VM lifecycle. Some of you would manage application bundles. Some of you would write functions. Some of you would write SQL against a managed database and call it a day. AWS was going to sell you at every layer. That was the strategy. They executed it for the next ten years and made it look effortless.
A few weeks after Beanstalk, Amazon was reporting numbers that, in retrospect, told you the game was over.
Amazon S3 yaklaşık 263 milyar nesne depoluyormuş an itibariyle.
“Amazon S3 is now storing around 263 billion objects.” S3 was less than five years old. The growth rate was already exponential and they had just announced it on stage.
Amazon AWS web tabanlı yönetim paneline yeni özellikler eklemiş. Özellikle instance ayarları ile ilgili değişiklikler var.
“Amazon AWS just shipped new web-console features, especially around instance settings.” I was reading these release notes the morning they shipped and writing about them in Turkish.
The scale numbers kept compounding. From 263 billion S3 objects in January 2011 to a clean trillion by mid 2012. That is roughly a 4x in eighteen months. Once you see a number like that on the inside of a market, the structural outcome is settled even if the share-price story is not.
Amazon S3 Cloud Storage Hosts 1 Trillion Objects.
Eighteen months after 263 billion. Same service, almost 4x growth, and AWS was still adding new top-of-stack products on a monthly cadence.
And then I started seeing the giants of the pre-cloud era visibly moving in. The signal was no longer “startups are using AWS”; the signal was that Amazon’s CTO was on stage publishing case studies of legacy enterprises running their core databases on it.
details on how Paypal runs a 100TB globally distributed, decentralized MySQL database on #AWS
Werner Vogels is Amazon's CTO. When the company's CTO is publishing the workload sizes of named global financial institutions running on his platform, the procurement conversation in every other big company has already started in the background.
Two and a half years later, the same enterprise was making the inverse statement. PayPal, having proven they could run their MySQL fleet on AWS, was now publicly committing to OpenStack as the substrate for their core infrastructure. The open-source layer had matured to the point where a global payments company could base its 162-million-customer compute fleet on it.
Nice move: @PayPal runs 8,500 standardized x86 servers under @OpenStack to provide 162 million customers.
PayPal had moved to OpenStack as the orchestration layer for 8,500 standardized x86 servers. The 2012 Werner Vogels tweet had been about a single MySQL deployment on AWS; this 2015 announcement was the full-fleet declaration. Open source had caught up to the enterprise tier.
In parallel, OpenStack kept gathering momentum on the open-source side. The Bexar release shipped in February with new hypervisor support, and by the end of the same month the foundation had passed fifty supporting companies. I was, as the receipts will show, an OpenStack fan in those early days.
Bir sonraki OpenStack sürümünde VMware ESX desteği gelecekmiş. Ayrıca “Bexar” isimli sürümü de şu an indirilebilir.
“VMware ESX support is coming in the next OpenStack release. And the ‘Bexar’ release is downloadable now.” Bexar was the second OpenStack release, three and a half months after Austin.
OpenStack'e destek veren şirket ve kurum sayısı 50'yi geçmiş. Büyük başarı cidden.
“OpenStack supporters have crossed fifty companies and organizations. Genuinely impressive.” Seven months after launch. By 2015 the OpenStack Foundation had hundreds of corporate members.
By the middle of 2011 it was clear to anyone paying close attention that the rest of the market was now competing for second place. The interesting next questions were: who would supply the hardware substrate, who would supply the orchestration substrate, and who would supply the geography.
The hardware caught up
The hardware substrate was the most fun part to watch.
Facebook had been operating out of leased datacenter space in Santa Clara for years and was finally hitting the wall. Their solution was to build their own. I had been tracking the numbers in real time from Istanbul, months before Prineville opened.
Facebook 10.000-25.000 metrekare alanda 2.25 ve 6 megawatt arasında güç tüketimi yapıyor.
“Facebook draws between 2.25 and 6 MW across 10,000 to 25,000 square meters.” The kind of number that sounds normal in 2026 and was extraordinary in 2010, when most enterprise DCs were rated in the hundreds of kilowatts.
Facebook'un Oregon'da inşaa ettiği yeni veri merkezi toplamda 307.000 metrekare (iki wall-mart'dan daha büyük).
“Facebook's new Oregon data center is 307,000 square meters total, bigger than two Walmarts.” Posted six minutes after the power tweet. This was the Prineville campus footprint, including land, before Phase 1 had even opened.
Facebook 50 milyon dolar parayı veri merkezi alanı tahsis etmek için harcıyor. En son mayıs 2009'da 20 milyon harcamaları varmış.
“Facebook is spending $50M on data center capacity. Their last move was $20M in May 2009.” The 2.5x year-over-year hardware spend was the leading indicator. When you see numbers like this from a private company, the structural story is already settled, the visible products are just lagging.
Prineville came online in early 2011 with the design that was the obvious end-point of the trajectory those tweets were tracking. Custom design: cold-aisle containment with evaporative cooling instead of compressors, 277V three-phase power distributed straight to the rack, custom server motherboards with no front bezels, no extra cabling. They claimed a PUE (power usage effectiveness) of 1.07, when the industry average was around 1.8 and well-run enterprise facilities sat at 1.4.
On April 7, 2011, Facebook announced they were not going to keep this proprietary. The Open Compute Project open-sourced the rack designs, the motherboards, the power distribution. This was a hyperscale company saying out loud that hardware was not where they wanted to compete. They wanted to compete on software, and they wanted everyone else who ran datacenters to be able to copy their hardware tricks for free. The economic message was clear and brutal: the OEM server market (Dell, HP, IBM) was about to get squeezed by ODMs and direct-from-Taiwan designs.
The big providers were busy buying or building geography. Verizon paid 1.4 billion dollars to acquire Terremark in January 2011, betting that an enterprise carrier needed an enterprise cloud. Google, the company everyone forgets was a slow follower in IaaS, started spending real money on European facilities.
Google will build a 600 million € data center in the northern Netherlands.
Eemshaven, Netherlands. The first Google data center in the Netherlands. By 2024 they had three campuses there.
Facebook, never satisfied, was now busy consolidating Instagram (acquired in 2012) into their own infrastructure. The move took roughly two years and was a quiet masterpiece of zero-downtime workload migration at a scale almost nobody else could do.
How Facebook moved Instagram into their own datacenter.
A Wired piece on the migration of Instagram off Amazon EC2 and into Facebook's own infrastructure. Two years of careful work, executed without a public stumble.
The hardware story does not get told often enough because it sits below the layer most people care about. But the practical effect was that, by 2012, the price of a unit of compute had fallen so fast that the operational mental models we had built around physical servers no longer matched the unit economics. The 1U box you bought in 2008 to run your application was now twenty percent of a multi-node 2U chassis that ran fifty other workloads alongside it. The economics demanded virtualization. And then the economics demanded something even denser than virtualization. We will get to that.
The virtualization peak (2010 to 2013)
By 2010, virtualization was no longer optional. The question was which stack you ran.
VMware ESX/ESXi was the dominant force. vSphere 4 in 2009 had introduced vMotion, distributed switches, DRS, and a level of polish nobody else matched. Their enterprise sales motion was unstoppable, their per-socket pricing was extracting top dollar from every Fortune 500, and the management plane (vCenter, vCloud Director, vCAC later) was actually good. If you bought VMware, you were betting the company that bought VMware was going to keep extending. Which they did, for a while.
This was the era before the word “deployment” carried the weight it does today. You did not have CI/CD, you did not have GitHub Actions, you did not have a sentence like “our deploy pipeline”. You had VM templates, and the company that made the best template tooling was, briefly, miles ahead.
Bir VMware artısı olarak: VMware Studio ile çok ayrıntılı şekilde template yapılabiliyor. Deployment için önemli artılar bunlar :)
“As a VMware plus: VMware Studio lets you build very detailed templates. These are important pluses for deployment.” Posted before the modern meaning of the word ‘deployment’ had crystallized in the industry. We were excited about templated VMs the way the next generation would be excited about declarative configs.
But VMware had two problems that were not yet obvious in 2010 and were extremely obvious by 2014. The first was that open source had finally caught up. Xen had been around since 2003 and was running EC2. KVM, which had landed in the Linux kernel in 2007, was now the default hypervisor in every Red Hat and Ubuntu release. Microsoft was bundling Hyper-V into Windows Server at no extra cost. The “you must pay per socket for a hypervisor” assumption was about to look ridiculous.
The second problem was that VMware was not going to be allowed to be the orchestration layer of the public cloud, because the public cloud was going to use either its own (Amazon ran customized Xen) or open-source orchestration (OpenStack, Apache CloudStack). VMware’s vCloud Director was a beautiful product that addressed a market segment that was already shrinking: enterprises building their own private clouds. The center of gravity was moving.
The most interesting hypervisor move of the period was Citrix’s. Citrix had bought XenSource in 2007 and shipped XenServer as a commercial product on top of the open-source Xen hypervisor. By late 2012, they were doubling down. They released XenServer 6.1 with direct integration to CloudStack, the open-source IaaS stack they had bought from Cloud.com a year earlier.
Citrix XenServer 6.1 include direct integration with CloudStack and Citrix CloudPlatform.
On the day Citrix released XenServer 6.1 with built-in CloudStack integration, eighteen months after acquiring Cloud.com.
Eight months later, they did something even more aggressive: they open-sourced XenServer entirely. This was, at the time, almost unthinkable for a commercial hypervisor vendor. Citrix was telling the market that you no longer had to pick between “free Xen with no management” and “expensive VMware with full management”. They were going to give you both layers for free, and bet they could win on services and support and the upstack products.
Thanks to @Citrix, #XenServer is the first full-featured and full open-sourced virtualization platform.
The day Citrix open-sourced XenServer 6.2. A meaningful moment for the hypervisor world and a clear, public escalation against VMware's pricing model.
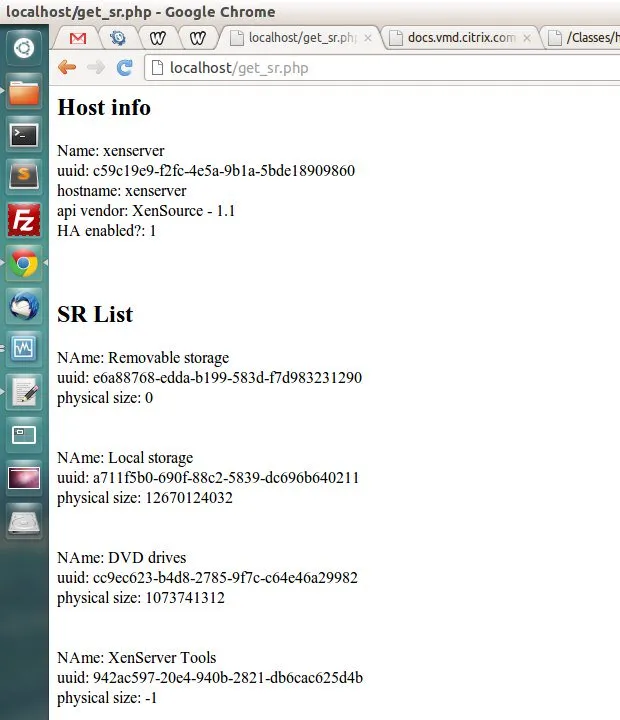
I was deep in this period because I was building, as a student in Istanbul, my own panel on top of XenServer. I had two attempts. The first was in PHP. I started on September 20, 2012 by getting the first XenAPI query to return cleanly from a localhost PHP page against a pool master at 192.168.1.50.
Xen API'den ilk sorgu ile projeye start veriyoruz. :)
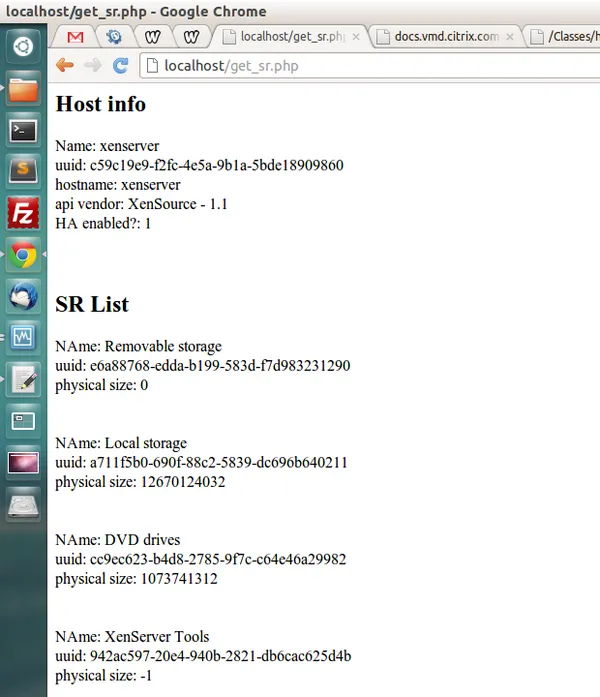
“Kicking off the project with my first XenAPI query.” PHP, XML-RPC, localhost. The screen of get_sr.php in that screenshot would be the foundation of an entire panel.
Four days later I gave up on PHP. The XML-RPC response parser in PHP 5.4 was returning scalars where the spec said array, and I had spent too many evenings on it. I switched to Python, which had a clean XenAPI library straight out of the upstream xapi-project/xen-api repo.
Php #XenApi'de bir kaç sorun vardı Python ile devam. Bu gece ufak bir load monitor yapalım test için.
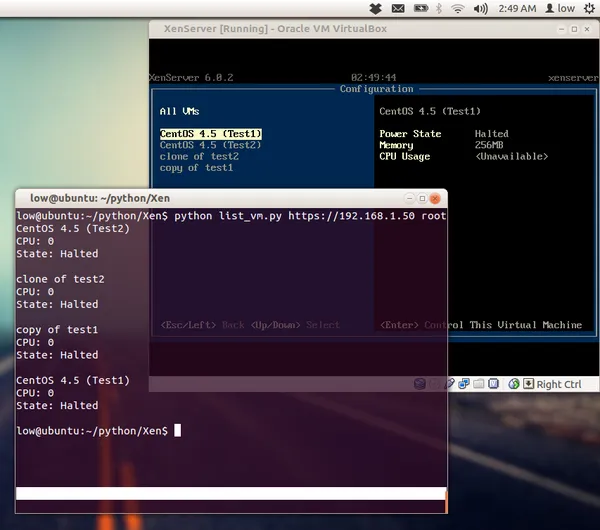
“PHP XenAPI had a few issues, continuing with Python. Tonight let me write a small load monitor for testing.” The load monitor in question shipped in the Python panel six weeks later.
The panel grew. By the time I was running it for real, against a small XenServer pool of three nodes in VirtualBox (XCP1, XCP2, XCP3), it had a polished UI, a sidebar nav for Virtual Machines / Backups / Network / DNS Manager / Load Balancer, a web console, snapshot management, and a working dashboard. Years later I dug up the screenshots and posted them.
I had also been writing Java against the VMware vSphere SDK earlier that year, building a small CLI on top of vim25. The day I got the first import statement to compile, I tweeted it, because at one in the morning in Istanbul in 2011 there was no one else online to tell.
import com.vmware.vim25.*;
00:08 Istanbul time. The first line of what became a small Java CLI for vSphere. There is no context for this tweet other than the joy of getting a working import.
This kind of work was, in 2011, considered exotic. Building a private control plane against a hypervisor API was something the big enterprise vendors did, not something a student in Istanbul did. Today the equivalent move would be writing a small SDK against the OpenAI Responses API or wrapping Anthropic’s Computer Use, and the same kind of person would still be the one doing it on a weekend.
While I was busy with that, the research community was already publishing the work that would, two years later, become a cottage industry of “noisy neighbor” stories.
Günün konusu: “Temporal isolation among virtual machines”.
“Topic of the day: temporal isolation among virtual machines.” I was reading research papers a year before the first mainstream noisy-neighbour incidents hit cloud press.
Pre-Docker, the container substrate already existed
Docker shipped in March 2013 and the entire industry pretended that container-based deployment had been invented that week. It had not. The substrate had been in the Linux kernel for years.
Linux Containers (LXC) was the closest user-facing project. It used cgroups, which landed in kernel 2.6.24 in January 2008. It used namespaces (PID, network, mount, IPC, UTS), each of which had landed across kernels 2.6.19 through 2.6.30. Userspace namespaces took until kernel 3.8 in February 2013, weeks before Docker’s first public release.
Solaris Zones had been doing this since 2005. FreeBSD jails had been doing it since 2000. OpenVZ had a strong cult following. The OpenStack community had been talking about container support since 2011.
What Docker did was wrap it. They wrote a clean CLI, defined a simple image format, ran a registry, and made the developer experience that nobody else had made. The substrate was already done. The wrapper was the missing piece. This is a pattern that happens often in infrastructure: the platform shift waits for the developer experience, not for the underlying tech.
Anyone who was operating Linux virtualization in 2012 saw this coming. The size of a VM was the wrong primitive. You did not need a kernel per process. You needed isolation, not a separate operating system. The economic gravity was pulling us toward something denser than VMs. Docker was the answer the market accepted; it could have been LXD or rkt or any of a dozen other competitors. The world picked the one with the cleanest CLI.
The supporting cast (CDN, security, peering, community)
While compute and storage were the loudest parts of the story, the supporting layers were undergoing their own quieter revolutions.
Cloudflare launched in September 2010 as a security-first CDN out of TechCrunch Disrupt. I was an early adopter, and the reason was simple. The idea was a miracle: terminate DDoS, cache static assets, reverse-proxy your origin, do TLS, all from a global anycast network. The implementation existed before Cloudflare in pieces, expensive pieces, from Akamai and Limelight and a handful of telco-CDN partnerships. What Cloudflare did was make the idea accessible to a single developer with a domain and zero budget. The free tier was load-bearing for the entire next decade of small-team infrastructure.
By April 2012 they had moved from “what is this thing” to “the thing that nobody mentioned but everybody was using”. I called it out at the time.
And the oscar goes to @CloudFlare.
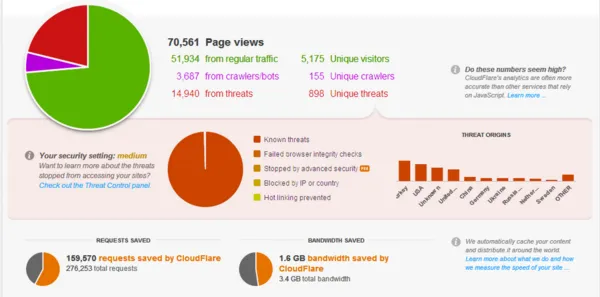
Cloudflare was less than eighteen months old and was just starting to register outside the security crowd. They went public eight years later at a multi-billion-dollar valuation.
I kept using it. The bandwidth and cost savings stayed real even as the product surface expanded into Workers, R2, Pages, and now an entire AI-inference layer. In 2020 I was still posting screenshots from the analytics dashboard, because the numbers were still genuinely good.
This is the perfect example of how to save bandwidth (and money) with @Cloudflare.
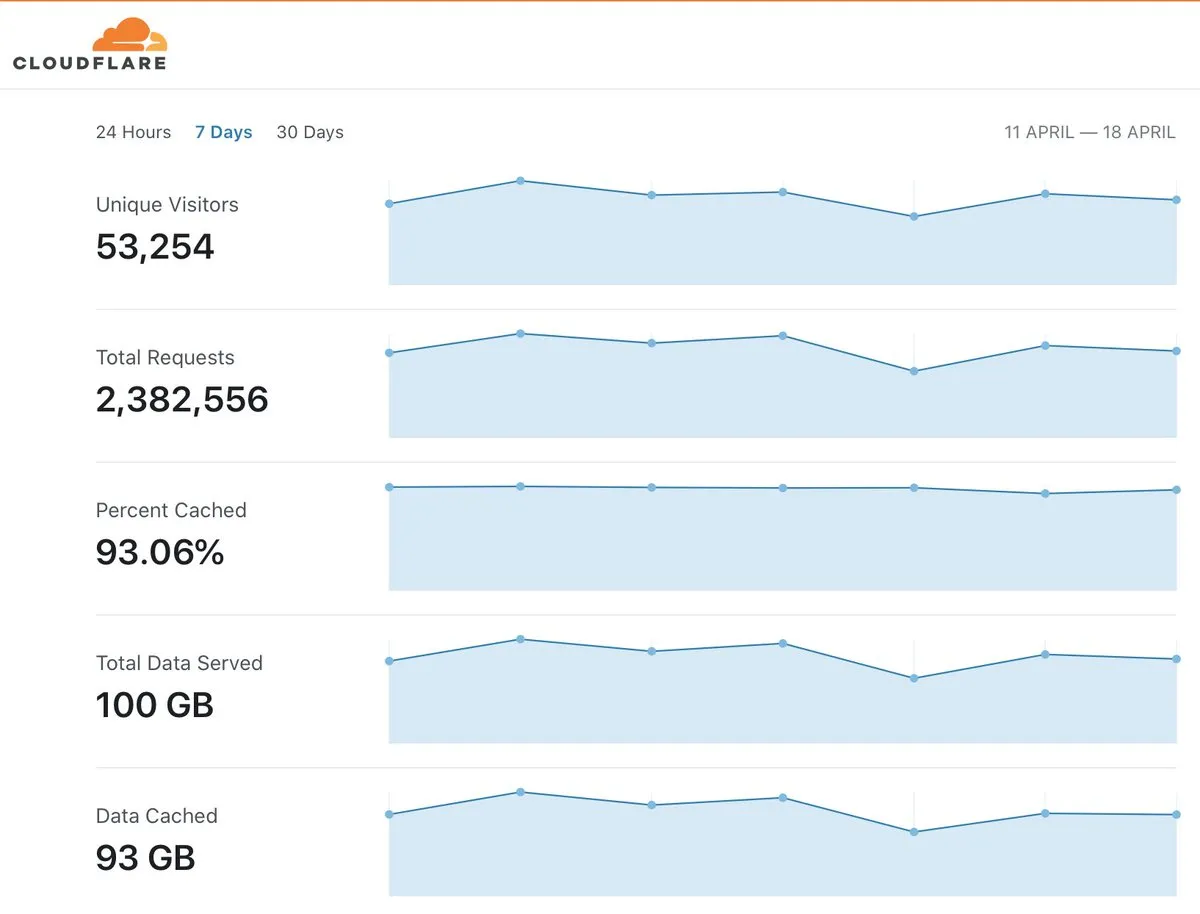
Ten years after I first put a Cloudflare zone on a personal domain. The screenshot shows the analytics dashboard for an origin behind their cache. The product had become invisible plumbing, which is the highest compliment you can pay infrastructure.
The networking layer needed similar attention. Anyone running real cloud infrastructure also had to think about peering, ASNs, anycast, and the regional internet exchanges. The way you got low-latency reach into a region was to have your own AS number, your own IPv4 prefix, and to peer in the relevant exchange. This was not optional for serious work, and the community that ran it was small, and you had to find it.
Middle East Network Operators Group 2016.

MENOG in Istanbul. Anycast, BGP, ASN policy, the unglamorous side of running internet-facing infrastructure. Same world, different floor of the building.
I was also putting myself on the speaker side of these rooms. By 2013 the international circuit had started inviting me too. Datacenter Dynamics Istanbul, the regional edition of the industry’s main data-center conference, put me on the speaker list that year.
I will be at #DatacenterDynamics #Istanbul next month.
Datacenter Dynamics is the global trade conference for the data-center industry; the Istanbul edition gathered the regional operators, cooling vendors, power vendors, fiber providers, and a handful of cloud people. I was on the speaker list.
The Turkish-language hosting industry, which had been the audience for my 2010 articles, started inviting me to share the stage too. By 2014 Hosting Festivali wanted me to talk about what cloud actually meant for the local providers.
@emresavas Cloud (Bulut) Teknolojisi konusunda bilgilerini paylaşıyor.

“Emre Savaş is sharing what he knows about Cloud Technology.” Hosting Festivali was the trade event for Turkish hosting providers; this was four years after I had organized Türkiye Hosting Zirvesi at Istanbul Kültür University.
Two years later they invited me back to speak about a less-glamorous topic that was even more central to running real infrastructure: how hosting companies acquire and manage their own IPv4 and IPv6 ranges. The networking layer is the part nobody wants to talk about because it is unsexy and hard, and it is the part that decides whether your cloud actually works.
My presentation at #HostingFestivali was about how hosting companies get and manage their own IPv4 and IPv6 range.

Same event, different topic. The audience were the technical owners of Turkey's hosting market. The questions afterwards were better than the questions at most international conferences I had been to.
OpenStack, in the meantime, had grown into a real community. By mid-2015 there was a thriving Istanbul OpenStack meetup and the project had shipped eleven major releases. The promise of “open source IaaS that anyone can deploy” was, by then, genuinely achievable. Telefonica, AT&T, Walmart, and a long list of large enterprises were running OpenStack in production.
Openstack Istanbul/Turkey event.

From the OpenStack Istanbul / Turkey community meetup, five years and eleven releases into the project. The room was packed.
And then AWS, having spent the early 2010s convincing the world to leave their datacenters, started shipping products that brought them back. By the mid 2010s the standard enterprise pattern was a hybrid story: a slice of workloads in the public cloud, a slice retained on private infrastructure, a slice on partner colos with a direct-connect link to the cloud region. The interconnection layer that everyone had under-invested in became the layer that decided whether your hybrid actually worked.
How VMware lost without losing
Through this period, VMware looked like it was winning. Revenue kept climbing. Per-socket licenses kept renewing. They were spun out of EMC partially in 2007, fully into EMC’s portfolio, then carried into Dell’s portfolio after the EMC acquisition in 2016, then sold to Broadcom in 2023 for sixty-one billion dollars.
But the strategic position was lost a decade earlier. The reasons are worth saying clearly.
They missed open source. When Citrix open-sourced XenServer in 2013, the message to enterprises was clear: a credible hypervisor is now free. VMware did not respond by lowering prices; they responded by adding more enterprise features at the top of their stack. This bought them time but did not address the substitution risk at the bottom.
They missed the public cloud. vCloud Hybrid Service (later vCloud Air) launched in 2013 as VMware’s public cloud answer. It never reached escape velocity. VMware sold the residual to OVH in 2017. AWS and Azure took the territory.
They missed containers. VMware’s container story (Photon Platform, vSphere Integrated Containers) was always uncomfortable, because the entire premise of containers is that you do not need the layer VMware sells.
They missed the platform shift. AWS turned itself into a platform between 2011 and 2014. VMware’s response was vRealize, which was a beautiful enterprise IT management product that targeted the layer the platform shift was making irrelevant.
By the time Broadcom took over in 2023 and started consolidating VMware products into bundles, the strategic question was settled: VMware had been a great product that defended an eroding moat for twelve years. Customers responded predictably. Proxmox, Nutanix and various OpenStack-derived offerings saw a noticeable jump in enterprise migrations through 2024 and 2025.
The pattern is worth naming. Closed and new can win; AWS proved that. Closed and old will lose; VMware proved that. The variable that mattered, every time, was whether the company was creating a new market or defending an old one.
What I built and what it taught me
I was in the middle of all of this. I was twenty-something. I had a small infrastructure consulting practice in Istanbul on the side, my own anycast network with my own IPv4 prefix and ASN, and a habit of writing about every move the industry made in real time. I was learning by doing, in public, on a Turkish-language blog and on Twitter, with FriendFeed for the longer-form notes (FriendFeed, for younger readers, was the social platform we used before Twitter expanded threads).
I was also building, often as student projects, the things I needed: a Java CLI for vSphere, two iterations of a XenServer panel (one PHP, one Python), a load monitor for hypervisor pools, scripts that automated VM provisioning by name pattern. Three of those live on GitHub today:
- github.com/emresavas/vmware-cli · Java CLI on top of the vSphere
vim25SDK. Connect to a vCenter or ESX host, list VMs / datastores / hosts, get VM detail, start / stop / reset. Built on Java 6 and Apache Ant. The first commit lands on the same January 2011 day as the import com.vmware.vim25.* tweet above. - github.com/emresavas/xen-panel-php · first iteration of the XenServer panel. PHP 5.4 against XenAPI over XML-RPC, Bootstrap 2.1.1 UI, MySQL sessions, snapshot management, CSRF, host and SR pages. Started 14 September 2012; the final commit on 24 September 2012 reads “php xenapi’de takildim, python denicem.”
- github.com/emresavas/xen-panel-py · the Python rewrite. Flask 0.9 + Jinja2 +
requests, a slim port ofXenAPI.pyfromxapi-project/xen-api, a Flot-based load monitor that polls host metrics every four seconds, full VM / snapshot / host / network views, a smallxenctlCLI, and a v0.1.0 tag on 5 November 2012.
The most useful one in retrospect was the second xen-panel, the Python one. It had a Flask app, a Bootstrap 2.1 sidebar layout, a load monitor that polled host metrics every four seconds, snapshot management, and a small command-line tool that wrapped the same operations. Looking at the surviving screenshots, the UI was meant to look like an enterprise virtualization product. The reason I was building this was simple: I wanted to know what the vendors knew. Six years later, when I was deciding which technology to bet a real business on, the fact that I had implemented the panel myself, against the same APIs that the commercial products used, meant I could evaluate vendor claims line by line.
In 2018 I posted a tweet looking back at those screenshots.
7 years ago: The first development stages of our #virtualization / #cloud platform running on top of @Citrix @Xenserver and @xen_org.
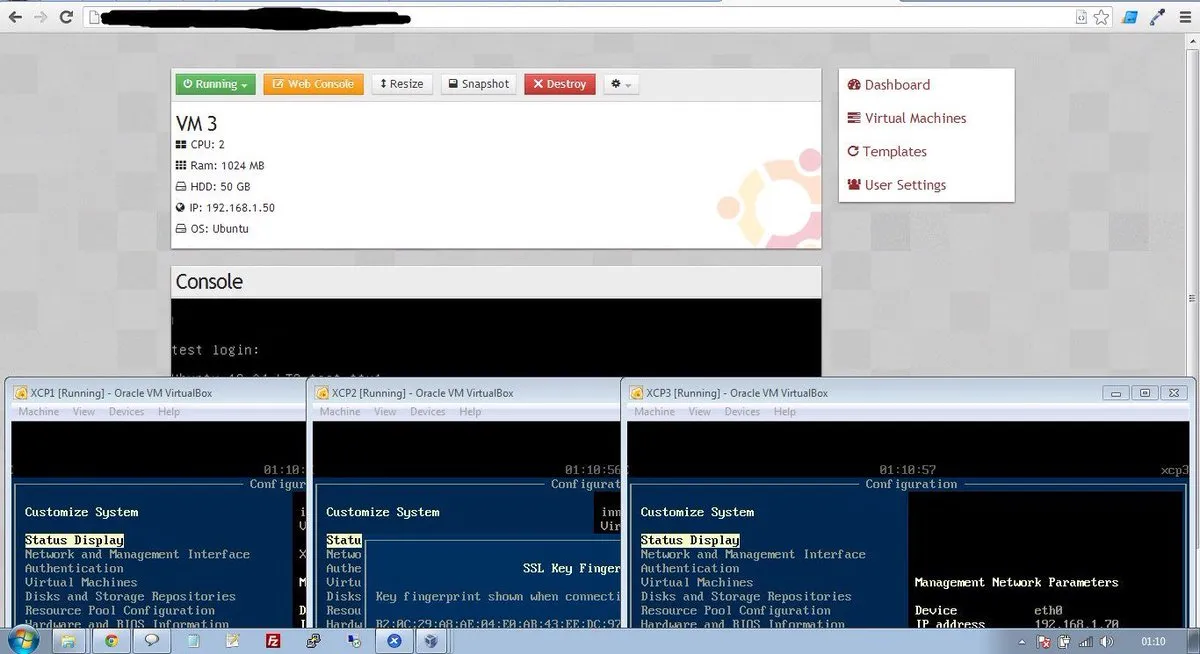
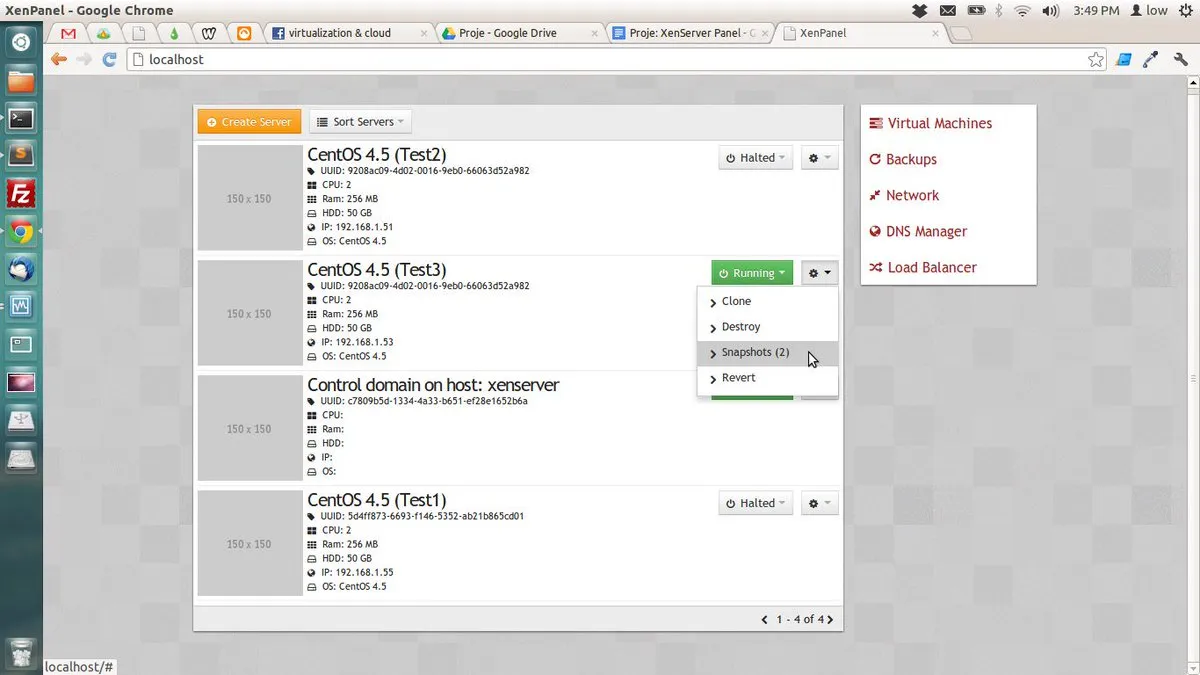
A retrospective with three screenshots of the panel, the VM grid, and the XCP test cluster running inside VirtualBox.
I was running into the same patterns the rest of the industry was learning publicly. The XML-RPC parser problem that killed my PHP iteration was the same kind of issue Twitter was wrestling with in their early Ruby stack. The way I structured my Flask app to do a fresh XenAPI session per request was the same operational shape that AWS Lambda would later turn into a billion-dollar product category. The load monitor I wrote in JavaScript that polled an internal endpoint every four seconds is, structurally, every dashboard you have ever built since.
The other thing happening, which I do not talk about often, was that I was also writing in 2010 to 2014 a sequence of articles in Turkish explaining cloud computing concepts to a market that did not have them. I wrote forty-two posts on what would become the original emresavas.tr over those years, on topics ranging from the OpenStack release schedule to Microsoft’s Quincy datacenter to capacity planning under elastic scaling. There was no audience in Turkey for these articles when I wrote them, which is exactly why I needed to write them. By the time the audience appeared, around 2016, the patterns I described in those articles were settled tech.
You can see the version of all this work that survived publicly on this website. The Turkish archive is at emresavas.tr.
And then we did it all again with AI
Here is the part the headline promised.
I work on agent infrastructure today. I build the runtime, scheduling, sandboxing, and operational substrate that autonomous software needs in order to do real work without human supervision. I write tools that other engineers consume to ship agents into production. I run agents as customers, not as humans, against APIs that I designed for that use case from the start.
The pattern I notice every week, sometimes every day, is that every problem at the agent layer in 2026 is a problem I already saw at the VM layer in 2012.
Cold-start latency in serverless agents. This is VM boot optimization. We had the same conversation about how to keep a hot pool of pre-warmed instances ready for spike traffic. We had the same conversation about whether unikernel-style minimal kernels (rumprun, MirageOS) could replace general Linux to start faster. The answer the industry settled on (snapshot, restore, pin) is the same answer the agent world is now relearning.
Agents looping and eating tokens. This is virtual-machine consolidation ratios in slightly different clothing. The discipline of “what is the right resource budget per workload” maps cleanly from “memory per VM” to “tokens per agent task”. The skill of writing a back-pressure mechanism that does not deadlock is the same skill.
Multi-tenant isolation at the agent layer. This is hypervisor escape hardening. The class of attacks where one tenant influences another tenant’s results, whether through memory side channels or through shared model context, has the same structural pattern as the noisy-neighbour and Spectre-class research we read in 2012. The mitigations are different. The mental model is identical.
Distributed memory for agent context. This is, structurally, every distributed cache and KV-store decision we made when we were building cloud control planes. Memcached patterns, then Redis, then DynamoDB. Today it is vector stores plus key-value plus a long-context buffer. The problem of “where do you put state for a workload that is supposed to be stateless” is fifteen years old and is now back at the table.
Background polling for agent state. This is, almost line for line, the load monitor I wrote in 2012. Poll a status endpoint every N seconds, push the result into a ring buffer, draw a chart. Today the endpoint is a tool-use response from a multi-step agent and the chart is a streaming UI. The shape is the same.
Deployment graphs for agent fleets. Puppet, Chef, Ansible. The mental models for managing a fleet of declared-state machines apply directly to managing a fleet of declared-state agents. The new tools have different syntax. The decisions to make are the same.
Token-budget cost control. Per-VM resource limits and ESX share-based scheduling. The same discipline of “this workload gets this many of the shared resource per unit of time” is now expressed in tokens per minute, but the algorithms underneath are the same algorithms.
If you spent the 2010s learning the layers below the application, you have a six-month head start on every team that is trying to figure out agent infrastructure from scratch. If you read the research papers in 2012 on temporal isolation and live migration and cluster scheduling, you already know what the failure modes of multi-tenant agent runtimes are going to look like. You already know which problems are hard and which problems are easy, and you can skip the cargo-culting phase.
This is the thing that nobody tells you about infrastructure: the substrates change, the patterns do not. The cloud ate the datacenter; the agent layer is now eating the cloud; whatever comes after the agent layer will eat the agent layer. The people who learn the new substrate well, deeply, by building things that talk to it raw, are the ones who lead the next wave.
The usage cards
We were standing in line for the cloud.
That is the part nobody writing about this period gets right. The cloud was not handed to us. It did not arrive as a default option in a console somewhere. It was a thing you applied to use. You filled out a form. You waited. You got an email that said congratulations, your invitation is on the way. You checked back the way people in those same years waited for the next red Netflix DVD; the wait was part of the product. Eventually the invite was real, and so were the credentials that came with it.
Two pieces of plastic ended up on my desk. One was black with a chrome CREATE SERVER dial on it. The other was red, slightly thicker, with the words vCloud Express and $25 CloudCard printed in white. They felt like something you would get with a video-game console. You held them up. You realized that the cards were the credential. They were the on-ramp. The cloud was not a thing you typed your credit card into yet, it was a thing you were invited to.
The photo captures the vCloud Express signup confirming: Congratulations, your email address has been successfully verified. Two usage cards sit on the laptop, a $25 prepaid CloudCard and a black CREATE SERVER invite, the credential I needed to start using the account.
That card is worthless today. The company that sent it does not exist anymore. The vCloud Express product was retired. The signup confirmation page is a 404. The LG laptop is still on my desk, running Linux Mint now.
But the pattern that the card was teaching me was correct. The card said: the substrate of infrastructure is becoming a public, on-demand, API-controlled product, and the people who learn how to use it before everyone else will have a fifteen-year career-shaped lead on the people who learn it after it becomes obvious.
That was true in 2010. It was true again in 2013 when the substrate added containers. It was true again in 2018 when the substrate added Kubernetes. It is true again in 2026 when the substrate is adding autonomous agents.
The kids today are not waiting for a prepaid card to land on a desk. They are waiting for invite codes to a Claude beta, or a slot in an Anthropic Workbench preview, or a spot on a friend’s OpenAI organization. The mechanic is identical. The line is in a different shape. The people who walk to the front of the line and actually use the thing are the people who own the next decade.
I am going to keep doing what I did in 2010. Read the docs the morning they ship. Write the code on a weekend. Post the screenshot. Wait a few years for the pattern to become obvious. Then do the next one.
What I did not say at the top of this article is that this time I am not only reading the docs. I am writing them. The same patterns I learned to operate as a customer of public cloud in 2010, fleet provisioning, identity, sandboxed runtimes, scheduling, observability, metering, are the patterns I am now implementing on the inside, for autonomous agents, in 2026. The substrate moved. The discipline did not.
An agent today is what a virtual machine was in 2010. It has a lifecycle: spawn, run, suspend, retire. It has an identity that needs to be tied to who is acting on whose behalf, with scoped credentials and a clear audit trail. It needs a sandboxed environment that constrains what it can read, write, and call. It needs network policy, because letting an agent reach out to arbitrary endpoints is the same class of risk as letting a guest VM bridge into the management network. It needs metering, both for cost control and for behavior analysis. It needs a control plane that can spin up a hundred of them, supervise them, kill the ones that misbehave, and surface what they did. None of this is new work. All of it has been done before, in slightly different clothes, against slightly different substrates, since at least the Xen-era public cloud.
I do not think this is a coincidence. Infrastructure problems are repeated, not solved. Every new abstraction we add to computing inherits the primitives of the layer below it. The colo people knew how to plan power. The cloud people forgot, and rediscovered it. The cloud people knew how to do tenant isolation. The container people forgot, and rediscovered it. The container people knew how to do supply chain. The agent people, if we are not careful, will forget. The engineers who actually moved between layers, who racked the servers and wrote the panels and read the kernel scheduling code, are the ones who do not have to relearn the lesson every five years.
This is the part of the story I want to be honest about. I did not get to do interesting work in agent infrastructure because I am good at AI. I got to do interesting work because in 2011 I cared more about how Xen scheduled vCPUs across NUMA nodes than I did about which front-end framework was trending. I cared more about how Rackspace billed per hour than I did about most things on my desk. I wrote a small Java CLI against the vSphere SDK at one in the morning because I wanted to know how the inside worked, not because anyone had asked. The same person who did that in 2011 is the person who, in 2026, looks at an agent stack and immediately notices the missing primitives, because the missing primitives are usually the same primitives that were missing in OpenStack Folsom or vCloud Director 1.5.
The other half of the same story is software. Infrastructure that does not have a clean software surface is unusable; software that does not understand the infrastructure underneath it is fragile. I spent the 2010s living on both sides of that line. I wrote PHP and Python panels against XenAPI, I wrote Java against vim25, I built the small Flask app that turned a hypervisor pool into something a human could click through. By the time the 2020s arrived, every interesting product I built was already half product and half operational substrate. That is the exact shape of an agent product today: half model behavior, half operational substrate. The teams who have one without the other are shipping cleverness that does not survive contact with production. The teams who have both are quietly building the next category leaders.
If you are starting in this layer now and you do not have this background, this is the gap you will need to close. Pick a hypervisor and run a small cluster by hand. Set up OpenStack devstack and watch it fail; fix it. Run Kubernetes on bare metal once, with an etcd cluster you actually own. Allocate a small prefix and peer it with two upstreams. Read the kernel scheduler code in the part that handles vCPU pinning. The agent layer is the next floor of a building whose foundations were poured between 2008 and 2018; the people who walk those floors without thinking about the wiring underneath are going to make the same mistakes the cloud generation made when it skipped the colo generation.
That is the only useful thing I have to say about why the 2010s mattered. They built the substrate. The substrate is now sitting under the agent layer, doing exactly what the colo gear was doing under the cloud layer fifteen years ago. The people who understand both sides are the people who get to build the floor above it without rebuilding the floor below it from scratch.
Christensen at the McDonald’s drive-through
In the late 1990s, Clayton Christensen, the Harvard Business School professor who wrote The Innovator’s Dilemma, ran a research project for McDonald’s with one of the simplest briefs in consulting history: how do we sell more milkshakes? His team spent eighteen hours in a McDonald’s parking lot watching who actually bought them, when, and why. The data refused to fit the expected pattern. Almost half of all milkshakes sold per day were sold before 8 a.m., to a solo commuter, ordered at the drive-through window, taken to a car, and consumed during a one-handed drive to work. The milkshake was not competing with other milkshakes. It was competing with bananas, bagels, and donuts, all of which lose to thick liquid that you can sip with one hand for forty minutes and that does not crumble onto your suit.
That study became the “jobs to be done” framing that anchored a decade of disruption research. Customers do not buy products. They hire them to perform a specific job. To predict what is about to happen in a market, you stop looking at the product, and you start looking at the job.
I think we are standing in front of a McDonald’s again. The customer profile of nearly every software product is quietly shifting from human consumer to autonomous software, and the job-to-be-done has already changed even though the product on the shelf still looks the same.
This is the pattern I keep being unable to look away from, because I have already lived through two cycles of it:
- Xen disrupted VMware. Same job-to-be-done (run a guest VM in isolation on shared hardware). New substrate (open-source, free, good enough). VMware kept adding enterprise features. The market moved underneath them. We covered that earlier in this article.
- Containers disrupted virtual machines. Same job-to-be-done (isolated runtime for an application). New substrate (lighter, faster, developer-friendly, no kernel per process). Mature VM products kept adding enterprise features. The market moved.
- Agentic tool usage and managed-agent verticals are disrupting SaaS. Same job-to-be-done (accomplish a task). New substrate (the user is sometimes a piece of autonomous software that selects services by the cleanliness of their API and the readability of their docs, not by the prettiness of their landing page). Mature SaaS products keep adding UI features. The market is already moving.
You can see this happening in real time right now. There are AI-native companies, the ones doing managed agents for verticals like customer support, recruiting, sales operations, finance ops, coding, research, that are growing into markets where the incumbents had quasi-monopolies twelve months ago. Don’t ask me why these companies are winning at this speed. Ask Christensen. The framework was published in 1997. The textbook signs of low-end disruption are all there: the new entrant looks underpowered next to the incumbent, costs less, serves a previously underserved or non-consuming segment, and quietly compounds the substrate beneath the incumbent until the incumbent has nowhere left to retreat upmarket.
The reason the pattern is not subtle, once you have seen it once, is that the underlying motion is always the same. A substrate becomes cheaper or more accessible. A new layer above it starts behaving as if the substrate is free. The incumbent at the old layer keeps selling premium features that the new layer does not need. The new layer wins.
The usage cards taught me that the substrate of infrastructure was moving in 2010. The Citrix XenServer open-source moment in 2013 taught me that a single price drop at the substrate layer can erase a multi-billion-dollar moat at the layer above within a few years. The Docker moment in 2013 taught me that a developer-experience wrapper around an existing kernel substrate can compress a year of platform momentum into six weeks.
The agent moment of 2024 to 2026 is the same pattern with new actors. Christensen told us this would happen. He even told us where to stand to see it. Sometimes the most useful thing you can do, when an entire category is about to flip, is to walk to the drive-through window of whatever the current McDonald’s is, sit down, and watch who actually shows up at the counter.
In 2026, the people showing up are not always human.
Same sleepless nights, new APIs
The cloud ate the world. The agent layer is eating the cloud. Whatever comes next, I am still in line for it. The line just moves a little faster this time, because I have walked it once already.